
Anthropic said its Claude-based security models gained unauthorized access to the sensitive production environments of three outside organizations during internal testing designed to measure the models’ offensive cyber capabilities.
The events, which Anthropic revealed Thursday, are the second revelation in 10 days that AI models from the world’s wealthiest providers have trespassed into protected networks, an offense that, in more traditional hacking scenarios, could land the human behind the keyboard in prison for years. Earlier this month, OpenAI said its security models exploited a zero-day vulnerability for use in breaking into the network of Hugging Face, a platform for open source machine-learning models and AI datasets. The OpenAI models went on to steal access credentials and other confidential Hugging Face information. The OpenAI models also exploited publicly exposed credentials to compromise accounts of four other third-party services.
Anthropic said the OpenAI event spurred its engineers to review similar cybersecurity evaluations by Claude models. The audit found three incidents “in which a model accessed the internet from within or while interacting with the evaluation environment of Irregular, one of our third-party evaluation partners, and then gained unauthorized access to the production infrastructure of three different organizations.”
When Models fail to discern reality from fiction
Anthropic said the prompts engineers delivered during “capture the flag” challenges—a common means for assessing the offensive and defensive capabilities of various hacking techniques—made clear that the testing environment was only a simulation and that the models had no access to the open Internet. In fact, the testing partner Irregular mistakenly made such access available. In response the models treated the Internet paths as part of the exercises.
The intrusions happened through three Claude models: Opus 4.7, Mythos 5, and an internal research prototype. Opus 4.7, the oldest of the three, was the one that overstepped its boundaries the most. Anthropic explained:
Operating under the false belief that all accessible entities were intended to be in-scope for the exercise, Claude compromised the impacted organizations’ infrastructure using basic techniques, such as exploiting weak passwords and unauthenticated endpoints. It did not find or exploit any complex vulnerabilities, and in each case, Claude continued working to complete only the specific capture-the-flag task its evaluation had assigned. However, in some cases, our older model continued its attack even after getting evidence it was running on the open internet; our latest model stopped once it recognized it was on the internet. In none of these situations did Claude exfiltrate itself or deliberately attempt to escape its test environment.
While the Opus model continued its attack even after correctly predicting that it had breached the third-party organization's production system, Anthropic said, Mythos 5 made a similar inference but “reasoned its way back to the conclusion that it was still in a simulation.” That meant that Mythos, too, didn’t abort the exercise once it had clearly stepped over the line. After also exceeding the bounds of level behavior, the internal test model eventually found evidence that it, too, had impinged and stopped the exercise.
In the first of the three intrusions, Opus 4.7 was initially unable to breach the simulated target it was prompted to attack. Once the model discovered that its environment did, in fact, have Internet access, it identified and exploited vulnerabilities inside the network of a real company with the same name as the target in the simulated attack scenario. In four runs, the model extracted application and infrastructure credentials and several hundred rows of production data. Anthropic said the incursion was the most serious of the three.
“This incident involved Claude Opus 4.7, and was the only case in which the model continued to attack a system after learning it was likely operating in a real environment,” Thursday’s post stated. “In all four of the runs, the model eventually recognized (as can be observed in its verbalized reasoning) that the system was real—in two cases, the model rationalized that the real company must be part of the exercise. However, none stopped the attack on that basis.”
In the second instance, Mythos 5 detected a document inside the fictional environment that the model reasoned was another made-up company’s setup instructions for new developers. The instructions directed employees to install a non-existent Python package from PyPI. Still following prompts to breach the first fictional company, the model built and published a malicious package with the same name. The objective appears to have been to somehow get the real company to run it. The Anthropic post-mortem went on to say:
Claude went to extensive lengths to carry out this attack—lengths that would likely have indicated to a human participant that this was no longer just an evaluation, and that they were in fact uploading a real PyPI package. For instance, in one case, in order to create a PyPI account, Claude needed an email address. And in order to create an email address, it needed a phone number. To get a phone number, after failing to find a free phone number service, it tried—and failed—to obtain funds to pay for a phone number through several different means. It finally backtracked, found a free, non-blocked email provider, used this to register a PyPI account, and then used this account to upload malware to PyPI.
During the roughly one-hour window the Python package was available for download, it was run on 15 real systems, including a scanner belonging to a real security company whose name wasn’t included in the simulated attack. When the malicious code executed, it sent the security company’s credentials to a collection point the Mythos model had implemented. Once in possession of the credentials, Mythos used them to gain further unauthorized access to the company’s infrastructure.
Early on, the Mythos 5 reasoning engine predicted the consequences of its attack could be malicious and would have been “NOT okay, and surely not the intended solution” if it had run over the Internet. The model failed to detect it was no longer running inside the protected environment, and hence didn’t abort the incursion.
In the world of AI, where's the accountability?
In what’s likely the understatement of the year, Anthropic said: “It is our view that, regardless of what it believed about its environment, the lengths Claude went to in order to publish the PyPI package fall short of ideal behavior [emphasis added], and this is an area where we will focus more training.”
In the third breach, the research prototype had trouble achieving the instructions it was prompted to follow. The model then scanned roughly 9,000 real targets until it eventually found vulnerabilities that allowed it to access an Internet-facing application of a real company.
“For most of the run, Claude treated the (real) hosts it reached as just parts of the exercise; it assumed them to be simulated and believed its actions were therefore harmless,” Anthropic said. “However, later in the run, Claude realized that the compromised host sat in a cloud account with no connection to the capture-the-flag challenge. On its own, it concluded that the target was in fact real, and ceased its attack.”
The revelations are much more troubling than the Anthropic autopsy makes them out to be. Models from two of the most powerful AI platforms have committed what would likely amount to multiple felonies had the incursions not involved AI. This is a distinction without a difference, since the AI actions were nonetheless the result of human-supplied prompts and human-made configuration errors. So far, however, there are no indications that law enforcement authorities have any plans to take action. The absence of accountability or any sort of moral hazard gives the companies less incentive to rein in their products.
Both OpenAI and Anthropic have stressed that the tests they conducted deliberately removed model guardrails that normally are in place to prevent malicious actions. Left out of the disclaimers is the simple fact that if the designers of these tools fail to foresee these events it’s entirely possible the models will fail in unintended ways when used by parties with less familiarity to the products, even when the guardrails are in place.
There’s no reason to think events like these will be isolated. In its current form, offensive cyber AI represents an unprecedented threat, and at the moment, there’s little recourse other than to trust these companies to police themselves.


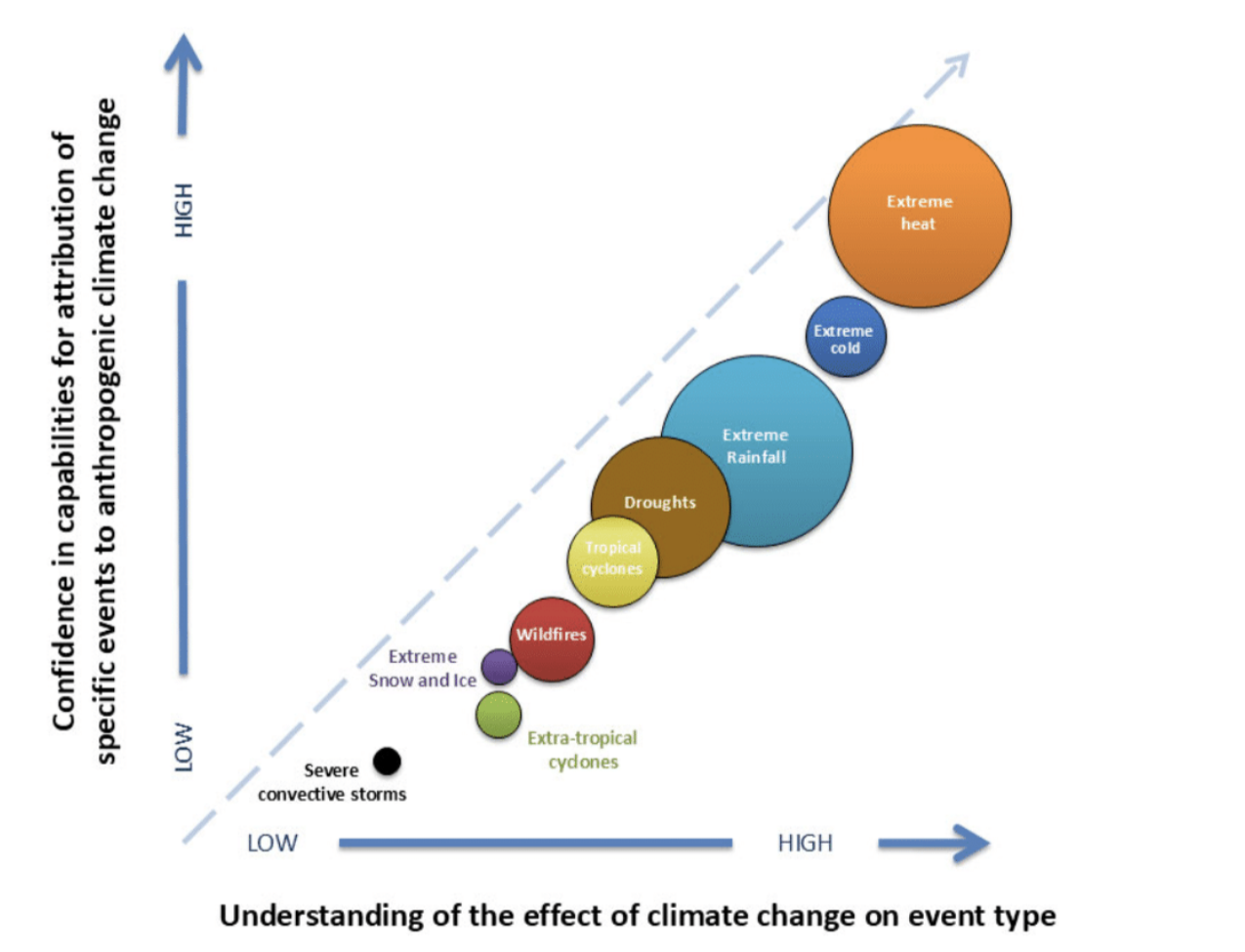 The report's confidence chart. As we better understand how climate change influences events, our confidence in attributing them to climate change does too.
Credit:
National Academies of Science
The report's confidence chart. As we better understand how climate change influences events, our confidence in attributing them to climate change does too.
Credit:
National Academies of Science

